The abstract nature of the Cardano consensus layer
This new series of technical posts by IOHK's engineers considers the choices being made
28 May 2020 21 mins read
As we head towards Shelley on the Cardano mainnet, we’re keen to keep you up to date with the latest news. We also want to highlight the tireless work going on behind the scenes, and the team of engineers responsible.
In this Developer Deep Dive series of occasional technical blogs, we open the floor to IOHK's engineers. Over the months ahead, our Haskell developers will offer a candid glimpse into the core elements of the Cardano platform and protocols, and share insights into the choices that have been made.
Here, in the first of the series, we consider the use of abstraction in the consensus layer.
Introduction
The Cardano consensus layer has two important responsibilities:
- It runs the blockchain consensus protocol. In the context of a blockchain, consensus - that is, 'majority of opinion' - means everyone involved in running the blockchain agrees on what the one true chain is. This means that the consensus layer is in charge of adopting blocks, choosing between competing chains if there are any, and deciding when to produce blocks of its own.
- It is responsible for maintaining all the state required to make these decisions. To decide whether or not to adopt a block, the protocol needs to validate that block with respect to the state of the ledger. If it decides to switch to a different chain (a different tine of a fork in the chain), it must keep enough history to be able to reconstruct the ledger state on that chain. To be able to produce blocks, it must maintain a mempool of transactions to be inserted into those blocks.
The consensus layer mediates between the network layer below it, which deals with concerns such as communication protocols and peer selection, and the ledger layer above it, which specifies what the state of the ledger looks like and how it must be updated with each new block. The ledger layer is entirely stateless, and consists exclusively of pure functions. In turn, the consensus layer does not need to know the exact nature of the ledger state, or indeed the contents of the blocks (apart from some header fields required to run the consensus protocol).
Extensive use is made of abstraction in the consensus layer. This is important for many reasons:
- It allows programmers to inject failures when running tests. For example, we abstract the underlying file system, and use this to stress-test the storage layer while simulating all manner of disk faults. Similarly, we abstract over time, and use this to check what happens to a node when a user's system clock jumps forward or backwards.
- It allows us to instantiate the consensus layer with many different kinds of ledgers. Currently we use this to run the consensus layer with the Byron ledger (the ledger that's currently on the Cardano blockchain) as well as the Shelley ledger for the upcoming Shelley Haskell testnet. In addition, we use it to run the consensus layer with various kinds of ledgers specifically designed for testing, typically much simpler than 'real' ledgers, so that we can focus our tests on the consensus layer itself.
- It improves compositionality, allowing us to build larger components from smaller components. For example, the Shelley testnet ledger only contains the Shelley ledger, but once Shelley is released the real chain will contain the Byron ledger up to the hard fork point, and the Shelley ledger thereafter. This means we need a ledger layer that switches between two ledgers at a specific point. Rather than defining a new ledger, we can instead define a hard fork combinator that implements precisely this, and only this, functionality. This improves reusability of the code (we will not need to reimplement hard fork functionality when the next hard fork comes around), as well as separation of concerns: the development and testing of the hard fork combinator does not depend on the specifics of the ledgers it switches between.
- Closely related to the last point, the use of abstraction improves testability. We can define combinators that define minor variations of consensus protocols that allow us to focus on specific aspects. For example, we have a combinator that takes an existing consensus protocol and overrides only the check whether we should produce a block. We can then use this to generate testing scenarios in which many nodes produce a block in a given slot or, conversely, no nodes at all, and verify that the consensus layer does the right thing under such circumstances. Without a combinator to override this aspect of the consensus layer, it would be left to chance whether such scenarios arise. Although we can control 'chance' in testing (by choosing a particular starting seed for the pseudorandom number generator), it would be impossible to set up specific scenarios, or indeed automatically shrink failing test cases to a minimal test case. With these testing consensus combinators, the test can literally just use a schedule specifying which nodes should produce blocks in which slots. We can then generate such schedules randomly, run them, and if there is a bug, shrink them to a minimal test case that still triggers the bug. Such a minimal failing schedule is much easier to debug, understand and work with than merely a choice of initial random seed that causes... something... to happen at... some point.
To achieve all of this, however, the consensus layer needs to make use of some sophisticated Haskell types. In this blog post we will develop a 'mini consensus protocol', explain exactly how we abstract various aspects, and how we can make use of those abstractions to define various combinators. The remainder of this blog post assumes that the reader is familiar with Haskell.
Preliminaries
The Cardano consensus layer is designed to support the Ouroboros family of consensus protocols, all of which make a fundamental assumption that time is split into slots, where the blockchain can have at most one block per slot. In this article, we define a slot number to just be an Int:
type SlotNo = IntWe will also need a minimal model of public-key encryption, specifically
data PrivateKey
data PublicKey
data Signature
verifySig :: Signature -> PublicKey -> BoolThe only language extension we will need in this blog post is TypeFamilies, although the real implementation uses far more. If you want to follow along, download the full source code.
Consensus protocol
As mentioned at the start of this post, the consensus protocol has three main responsibilities:
- Leader check (should we produce a block?)
- Chain selection
- Block verification
The protocol is intended to be independent from a concrete choice of block, as well as a concrete choice of ledger, so that a single protocol can be run with different kinds of blocks and/or ledgers. Therefore, each of these three responsibilities defines its own 'view' on the data it requires.
Leader check
The leader check runs at every slot, and must determine if the node should produce a block. In general, the leader check might require some information extracted from the ledger state:
type family LedgerView p :: *For example, in the Ouroboros Praos consensus protocol that will initially power Shelley, a node's probability of being elected a leader (that is, be allowed produce a block) depends on its stake; the node's stake, of course, comes from the ledger state.
Chain selection
'Chain selection' refers to the process of choosing between two competing chains. The main criterion here is chain length, but some protocols may have additional requirements. For example, blocks are typically signed by a 'hot' key that exists on the server, which in turn is generated by a 'cold' key that never exists on any networked device. When the hot key is compromised, the node operator can generate a new one from the cold key, and 'delegate' to that new key. So, in a choice between two chains of equal
length, both of which have a tip signed by the same cold key but a different hot key, a consensus protocol will prefer the newer hot key. To allow specific consensus protocols to state requirements such as this, we therefore introduce a SelectView, specifying what information the protocol expects to be present in the block:
type family SelectView p :: *Header validation
Block validation is mostly a ledger concern; checks such as verifying that all inputs to a transaction are available to avoid double-spending are defined in the ledger layer. The consensus layer is mostly unaware of what's inside the blocks; indeed, it might not even be a cryptocurrency, but a different application of blockchain technology.
Blocks (more precisely, block headers) also contain a few things specifically to support the consensus layer, however. To stick with the Praos example, Praos expects various cryptographic proofs to be present related to deriving entropy from the blockchain. Verifying these is the consensus layer's responsibility, and so we define a third and final view of the fields that consensus must validate:
type family ValidateView p :: *Protocol definition
We need one more type family*: each protocol might require some static information to run; keys to sign blocks, its own identity for the leader check, etc. We call this the 'node configuration', and define it as
data family NodeConfig p :: *We can now tie everything together in the abstract definition of a consensus protocol. The three methods of the class correspond to the three responsibilities we mentioned; each method is passed the static node configuration, as well the specific view required for that method. Note that p here is simply a type-level tag identifying a specific protocol; it never exists at the value level.
class ConsensusProtocol p where
-- | Chain selection
selectChain :: NodeConfig p -> SelectView p -> SelectView p -> Ordering
-- | Header validation
validateBlk :: NodeConfig p -> ValidateView p -> Bool
-- | Leader check
--
-- NOTE: In the real implementation this is additionally parameterized over
-- some kind of 'proof' that we are indeed the leader. We ignore that here.
checkLeader :: NodeConfig p -> SlotNo -> LedgerView p -> BoolExample: Permissive BFT (PBFT)
Permissive BFT is a simple consensus protocol where nodes produce blocks according to a round robin schedule: first node A, then B, then C, then back to A. We call the index of a node in that schedule the 'NodeId'. This is a concept for PBFT only, not something the rest of the consensus layer needs to be aware of:
type NodeId = IntThe node configuration required by PBFT is the node's own identity, as well as the public keys of all nodes that can appear in the schedule:
data PBft -- The type level tag identifying this protocol
data instance NodeConfig PBft = CfgPBft {
-- | The node's ID
pbftId :: NodeId
-- | The verification keys of all nodes
, pbftKeys :: [PublicKey]
}Since PBFT is a simple round-robin schedule, it does not need any information from the ledger:
type instance LedgerView PBft = ()Chain selection just looks at the chain length; for the sake of simplicity, we will assume here that longer chains will end on a larger slot number**, and so chain selection just needs to know the slot number of the tip:
type instance SelectView PBft = SlotNoFinally, when validating blocks, we must check that they are signed by any of the nodes that are allowed to produce blocks (that can appear in the schedule):
type instance ValidateView PBft = SignatureDefining the protocol is now simple:
instance ConsensusProtocol PBft where
selectChain _cfg = compare
validateHdr cfg sig = any (verifySig sig) (pbftKeys cfg)
checkLeader cfg slot () = slot `mod` length (pbftKeys cfg) == pbftId cfgChain selection just compares slot numbers; validation checks if the key is one of the allowed slot leaders, and leader selection does some modular arithmetic to determine if it's that node's turn.
Note that the round-robin schedule is used only in the check whether or not we are a leader; for historical blocks (that is, when doing validation), we merely check that the block was signed by any of the allowed leaders, not in which order. This is the 'permissive' part of PBFT; the real implementation does do one additional check (that there isn't any single leader signing more than its share), which we omit from this blog post.
Protocol combinator example: explicit leader schedule
As mentioned in the introduction, for testing it is useful to be able to explicitly decide the order in which nodes sign blocks. To do this, we can define a protocol combinator that takes a protocol and just overrides the is-leader check to check a fixed schedule instead:
data OverrideSchedule p -- As before, just a type-level tagThe configuration required to run such a protocol is the schedule and the node's ID within this schedule, in addition to whatever configuration the underlying protocol p requires:
data instance NodeConfig (OverrideSchedule p) = CfgOverride {
-- | The explicit schedule of nodes to sign blocks
schedule :: Map SlotNo [NodeId]
-- | Our own identifier in the schedule
-- (PBFT has such an identifier also, but many protocols don't)
, scheduleId :: NodeId
-- | Config of the underlying protocol
, scheduleP :: NodeConfig p
}Chain selection is unchanged, and hence so is the view on blocks required for chain selection:
type instance SelectView (OverrideSchedule p) = SelectView pHowever, we need to override header validation---indeed, disable it altogether---because if the underlying protocol verifies that the blocks are signed by the right node, then obviously such a check would be incompatible with this override. We therefore don't need anything from the block to validate it (since we don't do any validation):
type instance LedgerView (OverrideSchedule p) = ()Defining the protocol is now trivial:
instance ConsensusProtocol p => ConsensusProtocol (OverrideSchedule p) where
selectChain cfg = selectChain (scheduleP cfg)
validateHdr _cfg () = True
checkLeader cfg s () = scheduleId cfg `elem` (schedule cfg) Map.! sChain selection just uses the chain selection of the underlying protocol p, block validation does nothing, and the is-leader check refers to the static schedule.
From blocks to protocols
Just like the consensus protocol, a specific choice of block may also come with its own required configuration data:
data family BlockConfig b :: *Many blocks can use the same protocol, but a specific type of block is designed for a specific kind of protocol. We therefore introduce a type family mapping a block type to its associated protocol:
type family BlockProtocol b :: *We then say a block supports its protocol if we can construct the views on that block required by its specific protocol:
class BlockSupportsProtocol b where
selectView :: BlockConfig b -> b -> SelectView (BlockProtocol b)
validateView :: BlockConfig b -> b -> ValidateView (BlockProtocol b)Example: (Simplified) Byron blocks
Stripped to their bare bones, blocks on the Byron blockchain look something like
type Epoch = Int
type RelSlot = Int
data ByronBlock = ByronBlock {
bbSignature :: Signature
, bbEpoch :: Epoch
, bbRelSlot :: RelSlot
}We mentioned above that the Ouroboros consensus protocol family assumes that time is split into slots. In addition, they also assume that these slots are grouped into epochs. Byron blocks do not contain an absolute number, but instead an epoch number and a relative slot number within that epoch. The number of slots per epoch on the Byron chain is fixed at slightly over 10k, but for testing it is useful to be able to vary k, the security parameter, and so it is configurable; this is (part of) the configuration necessary to work with Byron blocks:
data instance BlockConfig ByronBlock = ByronConfig {
bcEpochLen :: Int
}Given the Byron configuration, it is then a simple matter of converting the pair of an epoch number and a relative slot into an absolute slot number:
bbSlotNo :: BlockConfig ByronBlock -> ByronBlock -> SlotNo
bbSlotNo cfg blk = bbEpoch blk * bcEpochLen cfg + bbRelSlot blkWhat about the protocol? Well, the Byron chain runs PBFT, and so we can define
type instance BlockProtocol ByronBlock = PBftProving that the Byron block supports this protocol is easy:
instance BlockSupportsProtocol ByronBlock where
selectView = bbSlotNo
validateView = const bbSignatureThe ledger state
The consensus layer not only runs the consensus protocol, it also manages the ledger state. It doesn't, however, care much what the ledger state looks like specifically; instead, it merely assumes that some type of ledger state is associated with a block type:
data family LedgerState b :: *We will need one additional type family. When we apply a block to the ledger state, we might get an error if the block is invalid. The specific type of ledger errors is defined in the ledger layer, and is, of course, highly ledger specific. For example, the Shelley ledger will have errors related to staking, whereas the Byron ledger does not, because it does not support staking; and ledgers that aren't cryptocurrencies will have very different kinds of errors.
data family LedgerError b :: *We now define two type classes. The first merely describes the interface to the ledger layer, saying that we must be able to apply a block to the ledger state and either get an error (if the block was invalid) or the updated ledger state:
class UpdateLedger b where
applyBlk :: b -> LedgerState b -> Either (LedgerError b) (LedgerState b)Second, we will define a type class that connects the ledger associated with a block to the consensus protocol associated with that block. Just like the BlockSupportsProtocol provides functionality to derive views from the block required by the consensus protocol, LedgerSupportsProtocol similarly provides functionality to derive views from the ledger state required by the consensus protocol:
class LedgerSupportsProtocol b where
-- | Extract the relevant information from the ledger state
ledgerView :: LedgerState b -> LedgerView (BlockProtocol b)We will see in the next section why it is useful to separate the integration with the ledger (UpdateLedger) from its connection to the consensus protocol (LedgerSupportsProtocol).
Block combinators
As a final example of the power of combinators, we will show that we can define a combinator on blocks and their associated ledgers. As an example of where this is useful, the Byron blockchain comes with an implementation as well as an executable specification. It is useful to instantiate the consensus layer with both of these ledgers, so we can verify that the implementation agrees with the specification at all points along the way. This means that blocks in this 'dual ledger' set-up are, in fact, a pair of blocks***.
data DualBlock main aux = DualBlock {
dbMain :: main
, dbAux :: aux
}The definition of the dual ledger state and dual ledger error are similar:
data instance LedgerState (DualBlock main aux) = DualLedger {
dlMain :: LedgerState main
, dlAux :: LedgerState aux
}
data instance LedgerError (DualBlock main aux) = DualError {
deMain :: LedgerError main
, deAux :: LedgerError aux
}To apply a dual block to the dual ledger state, we simply apply each block to its associated state. This particular combinator assumes that the two ledgers must always agree whether or not a particular block is valid, which is suitable for comparing an implementation and a specification; other choices (other combinators) are also possible:
instance ( UpdateLedger main
, UpdateLedger aux
) => UpdateLedger (DualBlock main aux) where
applyBlk (DualBlock dbMain dbAux)
(DualLedger dlMain dlAux) =
case (applyBlk dbMain dlMain, applyBlk dbAux dlAux) of
(Left deMain , Left deAux ) -> Left $ DualError deMain deAux
(Right dlMain' , Right dlAux') -> Right $ DualLedger dlMain' dlAux'
_otherwise -> error "ledgers disagree"Since the intention of the dual ledger is to compare two ledger implementations, it will suffice to have all consensus concerns be driven by the first ('main') block; we don't need an instance for ProtocolLedgerView for the auxiliary block, and, indeed, in general might not be able to give one. This means that the block protocol of the dual block is the block protocol of the main block:
type instance BlockProtocol (DualBlock main aux) = BlockProtocol main
instance LedgerSupportsProtocol main
=> LedgerSupportsProtocol (DualBlock main aux) where
ledgerView = ledgerView . dlMainThe block configuration we need is the block configuration of both blocks:
data instance BlockConfig (DualBlock main aux) = DualConfig {
dcMain :: BlockConfig main
, dcAix :: BlockConfig aux
}We can now easily show that the dual block also supports its protocol:
instance BlockSupportsProtocol main => BlockSupportsProtocol (DualBlock main aux) where
selectView cfg = selectView (dcMain cfg) . dbMain
validateView cfg = validateView (dcMain cfg) . dbMainConclusions
The Cardano consensus layer was initially designed for the Cardano blockchain, currently running Byron and soon running Shelley. You might argue that this means IOHK's engineers should design for that specific blockchain initially, and generalize only later when using the consensus layer for other blockchains. However, doing so would have important downsides:
- It would hamper our ability to do testing. We would not be able to override the schedule of which nodes produce blocks when, we would not be able to run with a dual ledger, etc.
- We would entangle things that are logically independent. With the abstract approach, the Shelley ledger consists of three parts: a Byron chain, a Shelley chain, and a hard fork combinator mediating between these two. Without abstractions in place, such separation of concern would be harder to achieve, leading to more difficult to understand and maintain code.
- Abstract code is less prone to bugs. As a simple example, since the dual ledger combinator is polymorphic in the two ledgers it combines, and they have different types, we couldn't write type correct code that nonetheless tries to apply, say, the main block to the auxiliary ledger.
- When the time comes and we want to instantiate the consensus layer for a new blockchain (as it inevitably will), writing it in an abstract manner from the start forces us to think carefully about the design and avoid coupling things that shouldn't be coupled, or making assumptions that happen to be justified for the actual blockchain under consideration but may not be true in general. Fixing such problems after the design is in place can be difficult.
Of course, all of this requires a programming language with excellent abstraction abilities; fortunately, Haskell fits that bill perfectly.
This is the first in a series of Deep Dive posts aimed at developers
*Unlike the various views, NodeConfig is a data family; since the node configuration is passed to all functions, having NodeConfig be a data family helps type inference, as it determines p. Leaving the rest as type families can be convenient and avoid unnecessary wrapping and unwrapping.
** Slot numbers are a proxy for chain length only if every slot contains a block. This is true for PBFT only in the absence of temporary network partitions, and not true at all for probabilistic consensus algorithms such as Praos. Put another way, a lower density chain may well have a higher slot number at its tip than another shorter but higher density chain.
*** The real DualBlock combinator keeps a third piece of information that relates the two blocks (things like transaction IDs). We Have omitted it from this post for simplicity.
Building new standards for privacy and scalability
IOHK joins the conversation around zero-knowledge proofs at the ZKP Workshop
20 May 2020 6 mins read
Building privacy and agency
In the age of information capitalism, data is a commodity which needs to be protected on an individual and global level. Every time someone makes a purchase, logs into an account, or accesses a website, metadata is connected to their individual IP address. Mass amounts of information move around the world every second but if it is not secured through encryption it can be exploited. The downstream effects of this can be benign, such as receiving targeted marketing. Or they can be dangerous like spreading political propaganda.
Privacy is central to the ethos of the crypto space. In terms of cryptocurrencies this has historically made many uncomfortable. Much of the early negativity around Bitcoin was linked to the perception that it was an untraceable enabler of the shadow financial system, from money laundering to global terrorism. But growth and greater awareness of data breaches, corporate and governmental overreach and ‘surveillance capitalism’ has shifted mainstream mindsets. Privacy has become a significant and legitimate concern for many, particularly with the arrival and potential fallout from the recent pandemic. Cryptography is recognized as an important tool for keeping institutional and governmental power in check and ensuring that data is kept by the people.
An individual’s personal information and metadata are their property. If they choose to share or sell access to their digital trail then it is their right. However, third parties currently take advantage of their stewardship over user information. This is why at IOHK we see it as our responsibility to investigate all technologies that might be used to enhance privacy, personal agency, and inclusive accountability.
New cryptographic approaches to address data security concerns have been a growing and significant area for IOHK research. We have produced more than 60 peer-reviewed academic papers, which have become an open-source, patent-free resource for everyone. Five of these papers relate to zero-knowledge proofs and their global application. They cover innovations in zk-SNARKs, privacy-preserving smart contracts and techniques for initializing these systems on blockchains in a more efficient and trustless way. But what are zero-knowledge proofs?
ZKProof Workshop
Zero-knowledge proofs, or ZKPs, are a cryptographic technique that, when applied to blockchains, can make them ultra-private and scalable. ZKPs allow information to be verified without being revealed to anyone but the intended recipient. In essence, zero-knowledge cryptography allows you to prove that you know something without revealing what that is. In the end, ZKPs protect people’s individual sovereignty and self-ownership. This is achieved using encryption to secure information while ensuring certainty and confidentiality when interacting with data sets, finances, and applications.
IOHK believes that these proofs represent an important step forward for universal inclusion, personal data management, and security. That is why we have been both sponsoring and participating in the third annual ZKProof Workshop, which concludes tomorrow.
This online conference brings together leading cryptographers, researchers and companies to advance the conversation around ZKPs. ZKProof’s open-industry academic initiative is focused on broad adoption of ZKP cryptography through the development of standards and frameworks. These international standards create a common language for applications, security, assurance and interoperability.
IOHK believes that the world will one day function through a nexus of interoperating distributed ledgers. This global network will combine legacy financial institutions, current tech companies, and emerging decentralized organizations. A global system like this will have to work equally for everyone. For that to occur, developers and engineers need to build common, trusted specifications and standards around privacy. They also need to ensure that immutable sources of information can be accessed by everyone. The workshop aims to define this framework for ZKPs. Ensuring privacy isn’t enough to build our worldwide system, we also have to make certain that it is accessible to all.
Power to the edges
IOHK has stated that its goal is to push financial and social power to the edges of society rather than siloing it at the center. To that end, we have to ensure that everyone has equal access to the single source of truth that is the blockchain. Things like state-dependent contracts and smart contracts require a large amount of space and computing power to maintain. This is a challenge given the fact that we want our platform to be equally accessible from high-powered desktops in London to cellphones in rural Uganda.
As blockchains grow they must also include multi-asset functionality, identity, and even voting. This is far from simply exchanging money or tokenized assets. All of these interactions involve maintaining and curating large amounts of information. For an individual to verify the source of truth from the node level of the blockchain, it would require petabytes and eventually exabytes of storage space. This is untenable for any user. Fortunately, ZKPs provide a solution to the problem.
Recursive construction of zero-knowledge proofs allows transactions on the distributed ledger to be truncated so that even as the blockchain grows, the necessary capacity to host the full node remains achievable for all participants. ZKPs bring both privacy and scalability together, which makes them a critical stream of research for IOHK engineers. The result of this is increased universal understanding and inclusion.
Inclusive accountability
Zero-knowledge cryptography isn’t just a scientific or academic stream of research. It is directly applicable to a variety of global challenges. ZKPs help create inclusive accountability. Inclusive accountability is the idea that there is universal verification for every actor running an algorithm on their computer or device. While ZKPs can be used to account for private monetary transactions they can also be used for casting votes, transferring records, and securing personal information. In essence, inclusive accountability is built into all of the most important processes that govern the world, laying a foundation of trust for everyone.
The focus of the ZKProof Workshop is to set standards that will pave the path to adoption of zero-knowledge cryptography. IOHK believes that these cryptographic tools are the key to addressing emerging challenges within our future financial and social frameworks. If you'd like to be a part of the conversation surrounding ZKPs you can still sign up to join the online ZKProof Workshop.
Check out our recent papers and our open source implementation of the Sonic protocol:
- Mining for Privacy: How to Bootstrap a Snarky Blockchain
- Sonic: Zero-Knowledge SNARKs from Linear-Size Universal and Updatable Structured Reference Strings
- Kachina: Foundations of Private Smart Contracts
- Ouroboros Crypsinous: Privacy-Preserving Proof-of-Stake
How pledging will keep Cardano healthy
Warding off attacks on the decentralized blockchain is just one benefit of the process
12 May 2020 5 mins read
As we approach Shelley on the Cardano mainnet, decentralization has, inevitably, become a topic of debate. Regardless of any initial founding intent, proof-of-work cryptocurrencies such as Bitcoin and Ethereum have become more centralized over time. The early days of Bitcoin enthusiasts mining blocks at the weekend are long gone and today we see a small group of specialized, professional mining operations dominating their respective chains.
In itself, this isn’t necessarily a bad thing – but if it happened to Cardano, it would run contrary to the vision of a decentralized, proof-of-stake protocol.
Cardano has been designed from the ground up with decentralization at its core and, in particular, in its stake delegation and reward mechanisms. On the Cardano network, pools above a certain size will not be competitive, and delegation rewards for everyone are optimal when there are many medium-sized pools. Every ecosystem benefits from diversity. Similarly, we believe that this approach offers the best balance between encouraging grass-roots involvement from skilled members of the community through to supporting those aiming to establish commercial stake pool businesses.
Pledging, and how it works
During pool registration, a pool operator can choose to pledge some personal stake to their pool to make the pool more attractive. The pledged amount can be changed on an epoch-by-epoch basis and will be returned when the pool is closed.
Everybody can operate a pool on the Cardano blockchain. No minimum pledge is required. Pool operators can optionally pledge some or all of their stake (or the stake of their friends and partners) to their pool to make their pool more attractive. The higher the amount of ada pledged, the more rewards the pool will receive, which will attract more delegation.
It is important to remember that there is also no maximum pledge, so a pool operator with a lot of ada to stake can maximize their own rewards by saturating the pool with the pledge and not attracting any delegation. This will of course only be possible for very few operators; most operators will try to attract delegation with a combination of pledge, low costs, low margin and good performance.
How attractive a pool is to delegators depends on four interacting elements:
- operating costs (the lower, the better);
- operator margin (the lower, the better);
- performance (the higher, the better);
- level of pledge (the higher, the better).
By pledging more, the pool operator can ask for a higher operator margin while still being attractive to delegators.
Why is pledging necessary?
Pledging provides a mechanism to encourage a healthy commercial ecosystem on the Cardano blockchain. The pledging mechanism is also necessary to protect the system against Sybil attacks. As I've discussed before, in a Sybil attack, someone with very little personal stake creates hundreds of pools with low margins and tries to attract the majority of stake to their pools. If this succeeds, they can control consensus and engage in double-spending attacks, create forks, censor blocks, and damage or even destroy the system.
By making pools with higher pledges more attractive, such attacks are prevented, because an attacker now needs to split their stake between many pools, making those pools less attractive and increasing the inherent cost of attempting a Sybil attack.
How influential will pledging be?
We face a classic trade-off here: we want the system to be as decentralized as possible and we want to give as many people as possible the chance to operate a stake pool, so pledging should not have a big effect on rewards.
On the other hand, we need to protect the system from Sybil attacks, and the higher the influence of pledging is, the more ada an attacker requires to succeed in such an attack.
The goal is clear: we want to set the influence of pledging as low as possible, while still being able to guarantee security.
How do we determine the influence of pledging?
The parameter that determines the influence of pledging will need to be set before the rollout of Shelley on the Cardano mainnet. However, the parameter has been designed to be flexible and adjustable over time. The Shelley Haskell testnet will provide an ideal opportunity to tune this parameter and test which values work and which do not. We’re also developing a calculator to help pool operators model different pledge amounts and work out how this might affect delegation and thus their rewards and revenues.
Reasonable values depend on many factors: How much stake does a typical pool operator own? How expensive is it to operate a node? How many people are interested in operating a pool? We gathered a lot of data during the Incentivized Testnet, and we will gain even more from the next testnet in close collaboration with our users.
We believe in our scientific approach and are confident that our design will lead to a decentralized, stable, and secure system – but science and mathematics only get you so far. You always have to make modeling assumptions, and no model can ever be as complex and colorful as the real world and the real people who make up the Cardano community.
We have already seen some very positive contributions and debate on the topic, including on Reddit and a recent Cardano Effect show. The Shelley Haskell testnets will be the perfect training ground for us to continue to debate, assess and iterate, collaborating with stake pool operators to see what is optimal for everyone. Just as we saw with the success of the Incentivized Testnet and the recently launched Daedalus Flight user testing, it’s again the time to draw upon the community’s help to put our research into practice.
From Byron to Shelley: part two, the journey to the mainnet
Continuing on to Shelley with the decentralization of block production
11 May 2020 5 mins read
Today, we’re kicking off the ‘Friends & Family’ testnet, which will allow us to establish a robust network to test and iterate, before we roll it out to the wider community. We’ve gathered a small number of around 20 ‘pioneers’ to help us with this important initial work. By the time you probably read this, they’ll be briefed and we’ll have things underway.
In my last blog, I outlined how the Shelley experience will roll out within clearly defined phases. These first three phases will involve exploring and testing the new Shelley capabilities via a series of testnets. I thought it might be useful to offer a glimpse ahead to provide some additional context.
The rollout of the testnets will happen very much in parallel with our continued progress towards mainnet. So alongside the work on the Haskell Shelley testnet, the mainnet will be systematically upgraded to support the Shelley era protocol, that will enable staking, delegation and metadata.
Similarly, IOHK’s block-producing and public-facing relay nodes on the mainnet will be upgraded so that they are ready for Shelley, and the Blockchain Explorer, Daedalus Wallet, Wallet CLI and other user-facing software will be polished so that it can be used for mainnet.
Users will soon be able to go to the official Cardano websites or other providers such as Yoroi, to download a new wallet – currently in development – that will work with both Byron and Shelley era blocks. The Shelley-era Daedalus wallet will contain all the logic for staking and delegation that has been tested on the Incentivized Testnet, plus new features that are specific to the full Shelley protocol. Stakepool operators, exchanges and others will also be able to download Shelley-compatible nodes and to adapt their own software to support the new Shelley client API. However, during this period, the mainnet will still be running in Byron reboot mode with federated consensus governed by the OBFT (Ouroboros Byzantine Fault Tolerance) algorithm. Think of it as a time when forward compatibility is being integrated but not yet ‘switched on’.
The move to Shelley will be accomplished using the new hard fork combinator that has been developed by IOHK.The hard fork combinator allows a node to transition from one blockchain protocol to another. The Cardano node software that is running on the mainnet will gradually evolve so that it is able to deal with both Byron era and Shelley era blocks, and will be modified to include the hard fork combinator. When the time comes to move the mainnet from the Byron era to the Shelley era, IOHK will trigger a hard fork.
‘Switching on’ Shelley
This will activate the hard fork combinator within the nodes, and the nodes will then change from only producing Byron era blocks to only producing Shelley era blocks. After the hard fork, no new Byron era blocks will be recorded on the blockchain, and the nodes will be able to support distributed block production, staking and delegation. They will have seamlessly switched from the OBFT to the Ouroboros Praos consensus mechanism. We will have entered the Shelley era on the mainnet.
Distributed stake pools and Decentralization of Block Production
Central to Shelley is the idea of decentralization. IOHK believes that companies, systems, and platforms run by a single individual or central authority are more vulnerable and less fair. This is why it is crucial that we move block production to our supporters rather than keeping the power contained within our organizations.
The Cardano blockchain currently operates on a federated basis. Effectively, nodes ‘controlled’ by IOHK and EMURGO are responsible for block production, while Daedalus wallet users act as the nodes of the network. Shelley will mark the ‘beginning of the end’ of that era, as we move from Byron’s static federated system to an active, decentralized system.
At the moment, core nodes and relays are owned and operated by IOHK. The network propagates through relays into each individual wallet. Once the system decentralizes, nodes will be run by stake pool operators and networked with individual wallets. Once control of the system is transferred over, the community will be fully running the Cardano ecosystem.
Federated Block Production (Byron)
Following the hard fork, IOHK’s existing core nodes will initially produce all of the Shelley blocks, as in the Byron era. However, this will change over time, under the control of the built-in d (decentralization) parameter. This parameter can be considered as a control valve that allows increasing amounts of decentralization.
In the decentralization phase, the federated system will still produce a (steadily decreasing) portion of the blocks. As this happens, stake pools will begin registering, operating, and producing blocks and will start to earn rewards in proportion to the stake that is delegated to them. As time passes, more blocks will be made by stake pools and fewer will be made by the core consensus nodes. The balance between the two will be controlled by the d parameter.
Distributed Block Production (Shelley and Beyond)
We will use metrics like the amount of ada that has been staked to determine how quickly to change the d parameter and so to decentralize the network. Once the network has fully decentralized, the stake pools will completely take over block production. At that point, we will then be able to shut down the core consensus nodes and disable the d parameter. This is the first step towards the full decentralization of Cardano. We will return to that in future blog posts, when we discuss some of the exciting developments that the Shelley mainnet will enable.
The road towards Shelley has been long but creating a global financial and social operating system takes time, scientific rigor, and the support of an informed, passionate community. As always, we thank you for your support and encourage you to follow our official channels closely as the Haskell Shelley testnet and subsequent phases roll out.
Combinator makes easy work of Shelley hard fork
A behind-the-scenes look with Duncan Coutts and Edsko de Vries
7 May 2020 11 mins read
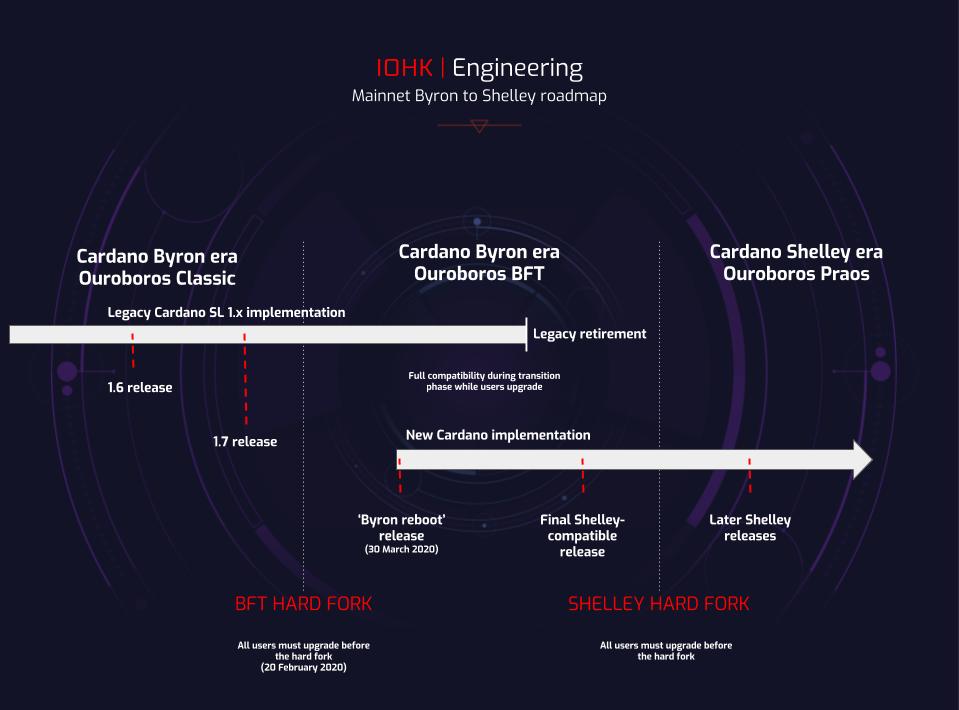
Since the launch of the Incentivized Testnet marked the coming of the Shelley era last year, the Cardano platform has entered a fast-moving period of development. The Ouroboros Classic consensus protocol has supported Cardano Byron and the ada cryptocurrency for the past 30 months, and we’ll soon be switching to Ouroboros Praos. This is the version of our proof-of-stake (PoS) protocol that will initially power Shelley as Cardano decentralizes. It builds in the staking process with monetary rewards for ada holders and stake pool owners.
We upgraded Cardano on February 20 with a hard fork that switched the mainnet from the original consensus protocol, Ouroboros Classic, to an updated version, Ouroboros BFT. This BFT hard fork began a transition period under Ouroboros BFT, a slimmed-down version of the protocol designed to help us make the switch to Praos, while still preventing any malicious behaviour. Many probably didn’t even notice. For Daedalus wallet users, it meant a standard software update. Exchanges had to upgrade manually, but they had several weeks to do this and we were on hand to help.
The next event was the ‘Byron reboot’ on March 30. This released totally new code for many of the Cardano components, including a new node to support delegation and decentralization, and future Shelley features. A big advantage of the new code base is that it has been redesigned to be modular, so many components can be changed without affecting the others.
In turn, the BFT will act as the jumping off point for the Shelley hard fork, which will happen once we’re happy with the Haskell testnet. This second hard fork will be a similar process to the February one for exchanges, ada holders and wallet users, and, hopefully, just as much of a non-event.
However, while everything looks smooth on the surface, there is a lot of hidden activity going on. Like a duck serenely swimming across a pond – while its feet are furiously paddling below the calm waters – our blockchain engineers are hard at it.
So, we sat down two of the leading engineers on the Cardano project, Duncan Coutts and Edsko de Vries, to find out how they’ve done it. Duncan has been Cardano’s architectural lead for the past three years, and between them, Duncan and Edsko have spent 35 years using Haskell, the programming language being used to develop Cardano.
Duncan, how did you do it?
As described in the Cardano roadmap, IOHK’s blockchain engineers believe in smooth code updates. Instead of trying to do the jump from Ouroboros Classic to Praos in a single update – which would be an incredibly complex task – it’s been a two-stage approach using Ouroboros BFT as an intermediary (Figure 1). The BFT code is compatible with both the Byron-era federated nodes and the Shelley-style nodes released in the Byron reboot. It's like a relay race: one runner (in our case, running one protocol) enters the handover box where the other runner is waiting; they synchronise their speeds (so they're perfectly compatible with each other) and then hand over the baton (operating the mainnet), and then the new runner with the baton continues from the handover box for the next lap.
The Daedalus Flight process has helped us quickly develop and test a new wallet and, once everyone is running that on the mainnet, and once we finish swapping over the core nodes, the old code is redundant. We are in that transition phase right now, with a new mainnet Daedalus wallet released on April 24.
Our aim is to have a ‘graceful entry into Shelley’, as IOHK chief Charles Hoskinson describes in his whiteboard video about the hard fork. A vital tool in making this move has been creating a hard fork combinator.
That sounds like farm machinery. What is it?
A combinator is just a technical term for something that combines other things. For example, addition is a combinator on numbers. A hard fork combinator combines two protocols into a single protocol. We call this a sequential combination of the two protocols because it runs the first protocol for a while and at some point it switches over to the second. In our case, this is two versions of Ouroboros as we move from BTF to Praos.
The clever part of all this has been the use of discrete modules that do their job, while knowing as little as possible about each other and the blockchain. Simplicity is the key here and this process of taking out the details we call ‘abstraction’. Most of the consensus modules don’t even have to know that they’re dealing with a cryptocurrency and could be putting pretty much anything on a blockchain. For example, we’ve done seminars using the example of a Pokémon ledger on a Ouroboros blockchain. The only thing that’s different is the ledger rules; the consensus is all the same. You just set it up – ‘instantiate’ it in the programming jargon – with the rules for playing Pokémon rather than for UTXO-style accounting.[For readers with a technical interest, watch out for Edsko delving further into the ‘abstraction’ process and combinators in a future blog post.]
You make it sound simple
In fact, it’s tricky because Cardano is running the ada cryptocurrency, and a pile of other things, at the same time. Think of it as changing all the wheels on a car while you’re driving along and towing a caravan. So we have to be sure we can do this in a totally reliable way.
We could have tackled this as a one-off task, but it made sense to do it in a generic way using a protocol combinator. We chose this route because we get a better result and the testing that is vital to ensuring the code works is made far easier. On top of that, there will be more hard forks to come, which made the choice even clearer. For example, as we near the culmination of Cardano’s development and move through the Goguen, Basho, and Voltaire eras, there will be at least one hard fork at each stage.
So how did you cope with the tricky bits?
Well, first off, we had to do it without research to turn to. The researchers describe a single protocol as a free-standing, perfect thing. But that’s not where we are. We are trying to run Praos after having started with a chain that was using something else. What Edsko’s working on, going from one protocol to another in a generic way, is just not covered in the research. And it’s hard, it’s complicated. All the details need a lot of thinking, a lot of scratching your head. But switching between Cardano code bases is not the sort of thing the academics can expect to get published. It doesn’t have a novel aspect and is seen as just an implementation issue.
Edsko, can you give us an example?
As Duncan says, for the researchers, these implementation issues are trivial but dealing with them is 99% of what we do. Take the problem of time for a blockchain. It’s what I’ve been banging my head against for a couple of weeks. Time is divided into slots where the chain can contain at most one block per slot. We often need to convert between slot numbers and time in the real world, for example when a node needs to know ‘Is it my turn?’ to generate the next block. This is fundamental to Cardano, but the length of a slot changes after the hard fork. For Byron, a slot is 20 seconds; for Shelley, it will be two seconds, or perhaps one. To really complicate things, the exact point of time when the hard fork is made is decided on the chain itself. Yet, I need to know when the changeover point is. It’s a quandary: to do slot conversions I need to know the state of the blockchain, but to know the state I need to know the slot conversions!
This is real chicken-and-egg territory with many complex things to disentangle. We have to be very precise with how we do things. It might be trivial in theory, but it’s very difficult to disentangle things and make sure it’s not a circular problem.
We can’t afford for it to be wrong, so how do you know you’re right?
Duncan: That’s an excellent question. My reply is that you come to the answer on two levels. The first is intellectual: you analyse the problem, you do the maths, you talk to colleagues and wrestle with it until you can see how it all fits together. Second, we do all our QuickCheck testing to give us the confidence that this does what we think it does. We do extensive testing that really takes us into the unusual cases that you might never think of, including this changeover. We can do 100,000 tests every time we change a line of code. [Lars Brünjes has written about how John Hughes, one of the creators of Haskell, has helped IOHK develop its testing strategies.]
Edsko: Yes, I agree with those two points. In terms of the combinator, I resolve these things by thinking about the guarantees that the code I write needs to provide, and which guarantees that it, in turn, needs from the ledger. I sketch a mathematical proof that this ‘if-then’ reasoning is indeed justified, and then turn to the formal method teams. The formal methods team are the people who set up the mathematical rules that describe the blockchain, and they can then tweak the rules in such a way that they provide the required guarantees.
In terms of Duncan’s second point, I know the time issue I mentioned above is correct by thinking hard mathematically, and by testing. Timing decisions are easy when we have the full blockchain, but are hard when we have to make predictions about the future. Fortunately, the way we set things up means I can easily create testing blockchains. So, I can create a full blockchain, then slice this chain in half. I take the first half and consider that to be in the present; and set the other half in the future. Then I can use the ‘present’ (first half) to make predictions about the ‘future’ (the second half) and verify them against the whole thing (on which the calculations are easy). If they match, then I know everything is OK.
When did you start on this?
Right after Duncan came up with the genius idea of the OBFT. So I’ve been thinking about the combinator on and off for about 18 months. It was a design goal from the very beginning of our modular rewrite of Ouroboros starting in October 2018, with my first commit to the GitHub repository. We had a prototype demonstration with OBFT and Praos soon after, in December 2018.
And how many people have been involved?
Duncan: Many people have been working on the consensus code, but whenever we have anything really hard, like this combinator, we give it to Edsko: he’s our software engineer extraordinaire! This is Haskell programming as free climbing, rather than climbing with the ropes of formal methods for support.
Any final thoughts?
Duncan: The code that was running is right now being phased out and pretty soon the code that was running Cardano a month ago will no longer exist. Once everyone is running the new code on the mainnet and once we finish swapping over the core nodes, the old code is redundant. We are in that transition phase right now and no one is shouting that the sky is falling. No one has noticed it.
Edsko: That is quite an achievement in its own right. The idea of OBFT was crucial in making the transition, but it’s not relevant any more once we make that transition to Shelley. This has been a way for us genuinely to ditch legacy code, which is often very difficult to do, as the banks know to their cost.
Duncan: And if it all works fine, you won’t notice anything.
Duncan and Edsko, thank you for your time. I think we’d better let you both get back to it.
Search blog
Recent posts
Oasis Pro deal will give developing world better access to financial markets by Anthony Quinn
26 September 2021
Cardano fund injecting $6m to support Africa’s pioneers by Anthony Quinn
25 September 2021
Cardano to integrate Chainlink oracles for real-time market data by Tim Harrison
25 September 2021